#下载
Windows版下载地址:https://mlocati.github.io/articles/gettext-iconv-windows.html
#翻译流程
- 在软件源码中使用相应的库将需要翻译的文字标记起来。比如C语言的
libintl,适合C++的 Boost.locale。 - 使用
xgettext.exe工具提取源代码中被标记的语句,生成 pot(portable object template)文件。 - 使用
msginit.exe工具将 pot 文件转化成一个特定语言版本的 po(portable object)文件。或者使用msgmerge.exe将更新了的 pot 文件与旧的 po 文件合并生成新的 po 文件。 - 编辑 po 文件(可使用 Poedit 等工具),开始翻译工作。
- 使用
msgfmt.exe工具将.po文件转换成.mo(machine object)文件。
#提取原文
从源码中提取原文用到的工具是xgettext。
#0x01 基本用法
在源码中标记需要翻译的字符串
1 | std::string str1 = boost::locale::gettext("Love"); |
提取命令
1 | xgettext.exe --from-code="UTF-8" -o my.pot main.cpp |
知识点:
- 工具默认提取关键字
gettext标记的字符串。 - 工具默认认为源文件是 ASCII 文件。
但既然是要做国际化支持,建议将源码文件改为 UTF-8 编码,通过参数--from-code来指示源文件的编码即可。生成的 pot 文件内容如下
1 | # SOME DESCRIPTIVE TITLE. |
#0x02 自定义提取关键字
xgettext.exe默认仅识别gettext关键字,但可以用--keyword参数指示额外的关键字以满足扩展需求
1 |
|
命令:
1 | xgettext --from-code="UTF-8" --keyword=_ --keyword=translate -o gettext.pot main.cpp |
#生成 po 文件
生成 po 文件用到的工具是msginit。
#0x01 基本用法
1 | msginit -i gettext.pot -o gettext.po |
得到po文件内容大概如下:
1 | # Chinese translations for PACKAGE package |
#0x02 指示目标语言及编码
输出的 po 文件默认使用本机区域设置,比如简体中文是zh_CN.GBK。
可以通过--locale参数指示 po 文件的语言和编码。格式遵循 ISO 639-1 和 ISO 3166-1 标准。
比如我想创建一个针对简体中文的翻译文件并采用 UTF-8 编码:
1 | msginit --locale=zh_CN.UTF-8 -i gettext.pot -o zh_CN.po |
但是charset却依然是GBK
1 | ... |
google找到了答案:因为 pot 文件没有编码信息
1 | "Content-Type: text/plain; charset=CHARSET\n" |
明明在 xgettext 参数中指定了 UTF-8,为什么 pot 文件没有信息?
1 | xgettext.exe --from-code="UTF-8" |
因为 xgettext 在提取原文过程中没有发现任何非 ASCII 字符,就会忽略掉 charset,也算是个BUG了。
当我手动修改 pot 文件编码后,再次生成 po 文件,charset 就变为了 UTF-8,但文件内容其实还是GBK。。。
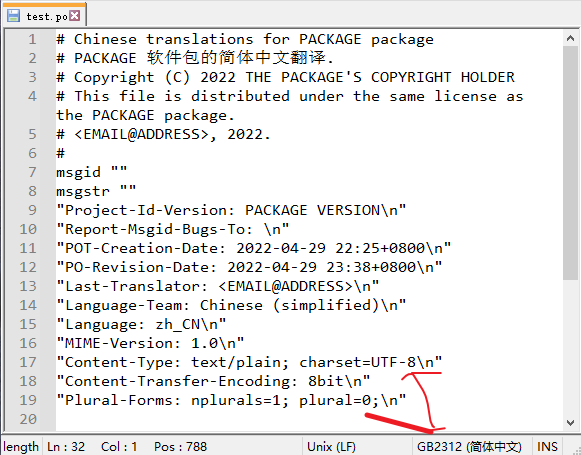
所以,解决这个问题需要做两件事
- 修改 po 文件的
charset为UTF-8 - 修改 po 文件编码为 UTF-8
每次去手动修改有点傻,我们可以在源码中标记一个UTF-8字符,但是翻译的时候忽略它,这样就能保证 pot、po文件的charset为UTF-8。
1 | //TRANSLATOR:无需翻译 |
这样就解决了charset的问题。文件自身编码问题可以用iconv.exe来转换,它已经包含在gettext工具包中了,所以最终的命令是:
1 | msginit -i test.pot -o zh_CN.po.tmp |
#生成 mo 语言文件
1 | msgfmt -o test.mo zh_CN.po |
#更新 po 文件
在软件升级迭代的过程中,待翻译原文也会发生变化,如增加、删除等,这就需要将 pot 文件中变动的内容更新至 po 文件,而不是重新生成一个新的 po 文件。这就需要用到msgmerge。
1 | msgmerge -U zh_CN.po test.pot |
-U表示更新现有 po 文件,按位置看,第一个文件就是被更新的目标文件。
当然也可以用-o参数创建一个新的 po 文件:
1 | msgmerge -o new.po zh_CN.po test.pot |
知识点:
- 新文件中词条如果有译文,任何情况下都不会被覆盖。
- 通过
compendium参数指定翻译文件对空词条进行填充。
1 | msgmerge --compendium dict.po -U target.po new.pot |
注意,引用的文件可以是 pot 文件,也可以是 po 文件。
#合并多个 po 文件
一个软件项目可能含有多个模块,每个模块都有自己的翻译文件,有大量重叠的内容,完全可以将多个 po 文件合并为一个。
1 | msgcat -o all.po 1.po 2.po |
默认合并规则:
- 对于相同的原文,如果仅有一个被翻译了,则采用它。
- 对于相同的原文,如果有不同的翻译,则会合并所有的翻译,需要人工处理
1 | #: main.cpp:21 main.cpp:25 |
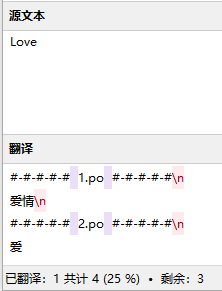
如果想避免重复的翻译内容被合并,可以使用use-first参数,表示采用找到的第一个可用的翻译。
1 | msgcat --use-first -o all.po 1.po 2.po |
#参考
msginit
GNU gettext工具简介
gettext使用
Generate UTF-8 dictionaries using gettext