#字符集选项

使用Unicode字符集后会在编译选项上附加_UNICODE和UNICODE这两个宏。
- 带下划线的版本会影响 C 运行时头文件默认处理的字符集。因此,如果定义了
_UNICODE,则_tcslen将映射到wcslen而不是strlen。 - 不带下划线的普通版本会影响 Windows 头文件默认的字符集。因此,如果定义了
UNICODE,则GetWindowText将映射到GetWindowTextW而不是GetWindowTextA。
当选择使用多字节字符集时,会在编译选项上附加_MBCS宏,不过这个宏可有可无,可能是因为历史原因一直保留着。因为在头文件中都是检测_UNICODE或UNICODE宏,而不是检测_MBCS。
字符集选项与字符编码没有太大关系,它仅用于一些关于字符函数的映射关系。
今天,永远应该选择 Unicode 字符集,多字节字符集是过时的选项,常见于一些古老的程序。
#/source-charset 选项
/source-charset 选项的作用是告诉编译器对于非Unicode编码的源文件使用什么编码方式读取文件。
- 编译器会检测源文件编码是否为
Unicode,比如UTF-8或UTF-16,如果是Unicode,则忽略/source-charset选项。 - 如果源文件不是
Unicode,则使用/source-charset指定的编码读取文件,如果未设置/source-charset,则使用ANSI编码。
如果源文件编码与/source-charset指定的编码不同,则可能出现 C4566 警告,这会导致文字乱码。

在实践中,总是将源文件保存为UTF-8编码是不会错的。可 VS 总是默认将非Unicode源文件保存为ANSI编码,不过我们可以借助插件来强制保存为UTF-8:
Format on Save
Format on Save for VS2022
Force UTF-8 (No BOM) 2022
Force UTF-8 (With BOM) 2022
Fix File Encoding
#/execution-charset 选项
/execution-charset 选项的作用是告诉编译器在 PE 文件中用什么编码存储字符串。
比如代码:
1 | ::MessageBoxA(nullptr, "1111哈哈", "", 64); |
用16进制工具查看 PE 文件,搜索相关字符
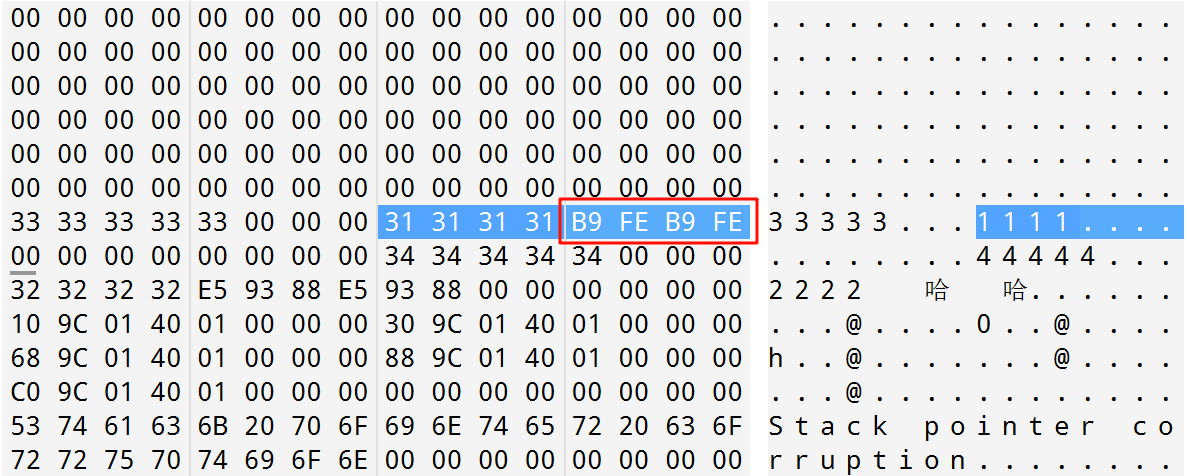
其中B9 FE B9 FE正是哈哈的 GBK 编码。因为当不设置/execution-charset选项时,默认采用本机编码。
如果修改为/execution-charset:utf-8后:
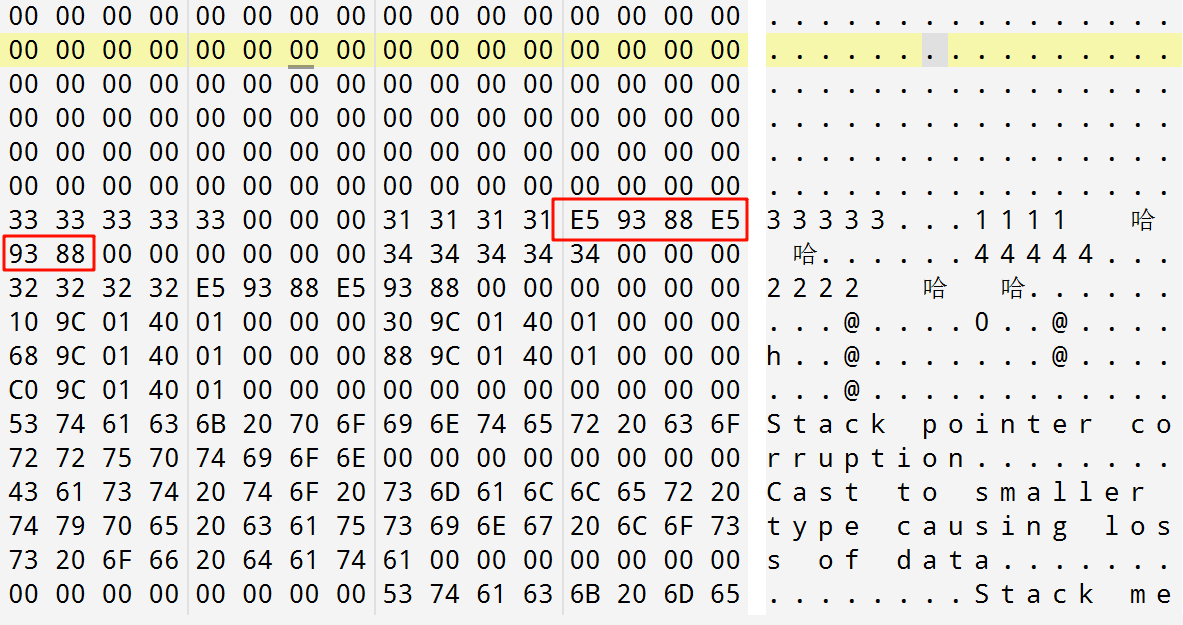
此时哈哈的16进制变为了E5 9E 88 E5 9E 88,这正是UTF-8编码。
上面的例子出现乱码,因为我用的是中文系统,A 后缀版本的 API 函数会认为字符串是 GBK 编码,于是就乱码了,所以如果用了/execution-charset:utf-8选项后,又用的是 A 版函数,则要在传入字符串的地方先将编码转换为Unicode。
#/utf-8 选项
一句话:等同于设置了/source-charset:utf8 /execution-charset:utf-8。
#UTF-8 版 Win32 API
因为历史原因,Win32 API 的 A 后缀版函数认为字符集都是ANSI,这导致在跨平台开发中,需要在调用系统 API 的地方先将UTF-8字符转换为UTF-16后再调用 W 后缀的函数,相当繁琐。
为了让 A 后缀的系统函数支持UTF-8,微软在 Windows 10 1903 上支持在manifest文件中提供activeCodePage属性。
1 |
|
这样就能在调用 A 后缀系统函数的地方传入UTF-8字符串了。
注意,它仅在Windows 10 1903以上的系统上有效。
不过根据官方文档描述,GDI 还不支持,还要修改系统设置,所以目前来看这个方案用起来还是那么丝滑。
#UTF-8 和 UTF-8 BOM
带BOM签名的 UTF-8 常见于 Windows 平台,而在 Linux 生态中常见的是不带BOM的 UTF-8。
- 带
BOM:让软件更精准的识别而不是靠猜,但一些古老的软件可能不支持。 - 不带
BOM:对一些古老的软件兼容性好,特别是 Linux 平台,但是在 Windows 下一些软件可能要猜测编码。
所以,选择哪种编码就是在兼容性与准确性之间的抉择。
不过,现如今各种工具软件基本都支持UTF-8 BOM了,所以可以优先考虑用UTF-8 BOM。
#建议
- 如果仅在 Windows 平台,源文件用
UTF-8 BOM编码存储。字符串用宽字符,Win32 API 函数用 W 后缀的版本。 - 如果仅在 Linux 平台,源文件用
UTF-8编码存储。字符串用窄字符。 - 如果需要跨平台,源文件用
UTF-8 BOM编码存储。字符串用窄字符,在使用 Win32 API(W后缀版本)函数的地方转换为宽字符。
#相关阅读
Why both UNICODE and _UNICODE?
代码页标识符
在 Windows 应用中使用 UTF-8 代码页